This morning someone asked me how big Scrivener’s code base is, and I didn’t know how to answer - yet it’s something I’ve been wondering myself. It comes up occasionally, usually in two situations: 1) Someone writes to me wanting to know how much code it took to create Scrivener, because they have an idea for a program and wonder what’s involved; 2) Someone is insisting that I could port Scrivener to platform X or “just add” Y “easily enough” and is getting uppity that I’ve said no, so I want to puff out my chest and huff, “Look, I have written six billion lines of code mostly unique to the Mac platform and I’ve already got grey in my hair - coding Scrivener ain’t like dusting crops, kid!” (These exchanges usually end with me apologising for something.)
Of course, how much code is behind any given program is misleading, and to a large extent rather meaningless, too. For a start, any Cocoa program stands on top of the vast amount of code written by Apple, so counting how much code you have written for a Cocoa application with a view to calculating how much work it would take to port it to another platform (even the iPhone or iPad) would be pointless, as it would not include all the extra code you might need to write to replicate features provided in Cocoa by Apple. Also, small programs with less code are often better for particular jobs than large programs with reams of code. For instance, Bean contains much less code than Microsoft Word, but it’s much nicer to user for basic documents. On the other hand, a good program that appears very simple to the user may contain a great deal of code that checks for potential errors. Besides, from a programming point of view, there’s nothing better than cutting code. It’s always a good feeling when, upon reviewing a section of code you wrote ages ago, you slap your forehead and realise that you have written 50 lines that could have all been done in one. (There’s a great story about an Apple Lisa programmer who, when forced to fill in a form declaring how many lines of code he had written that week for the sake of proving progress to the management, wrote “-2000” - they didn’t use the forms much longer.) Less code is usually better, but sometimes more lines of code is necessary for the sake of readability. You might be able to cram ten lines of code into one, but if you come back to it two years later and have no idea what that line is for, then what was the point? It would have been better to have written ten lines of code with well-named variables, or at least to have made more space for meaningful comments.
Still, caveats aside, after having worked on a project for more than five years, it would be interesting to know how much code you have ended up with. Yes, it’s meaningless - the results of your labour are measured by the quality of the application and not by the quantity of code - but the obsessive compulsive, anal retentive in me wants hard figures (whatever a “hard figure” is - a die-cast Arnie?).
How do you measure the size of your code base, though? It’s not as simple as it at first sounds. Do you count the number of files you have generated? But then, in object-oriented programming, each class has at least two files, and sometimes more if you have created categories. So do you just count the number of different class files you have created? Each of those could contain wildly different amounts of code, though, so maybe you should could the total lines of code in all? But then, even counting lines of code is far from straightforward. For a start, there will be lots of blank lines - so what about if you count only the lines of code that aren’t blank? But what about lines that don’t contain any statements, just an “if (something)” or an end bracket? Okay, so how about we just count lines that have a semi-colon in them, as that indicates the line has a statement in it. On top of all of this, though, when thinking about text, I like to think in word and character counts - if I’d been writing instead of coding, how many books could I have written (or, more accurately, agonised about not writing)?
Well, in the name of procrastination, I decided to spend this morning writing an application that would count all of these things, as it seems to me that they all have something to say about how much code you have written. There are a few other apps out there that will count lines of code and so on, but after spending twenty minutes searching, I figured I would just write my own. I called it “Xcode Statistician”, and if you are a programmer you can run your own Xcode project through it by downloading it from here:
http://www.literatureandlatte.com/freestuff/XcodeStatistician.zip
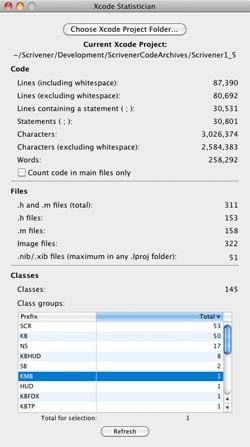
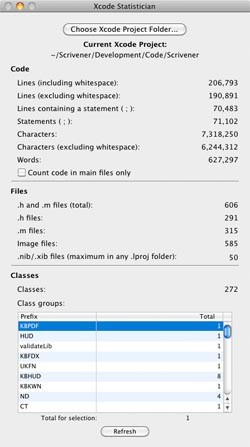
Here are the results of running the Scrivener 1.5 code base through it:
0 Comments
Please sign in or register to comment on this post.
Register
Sign in
Forgotten password